上周两个应用CPU涨到500%,查看监控Major GC次数、耗时都暴涨:
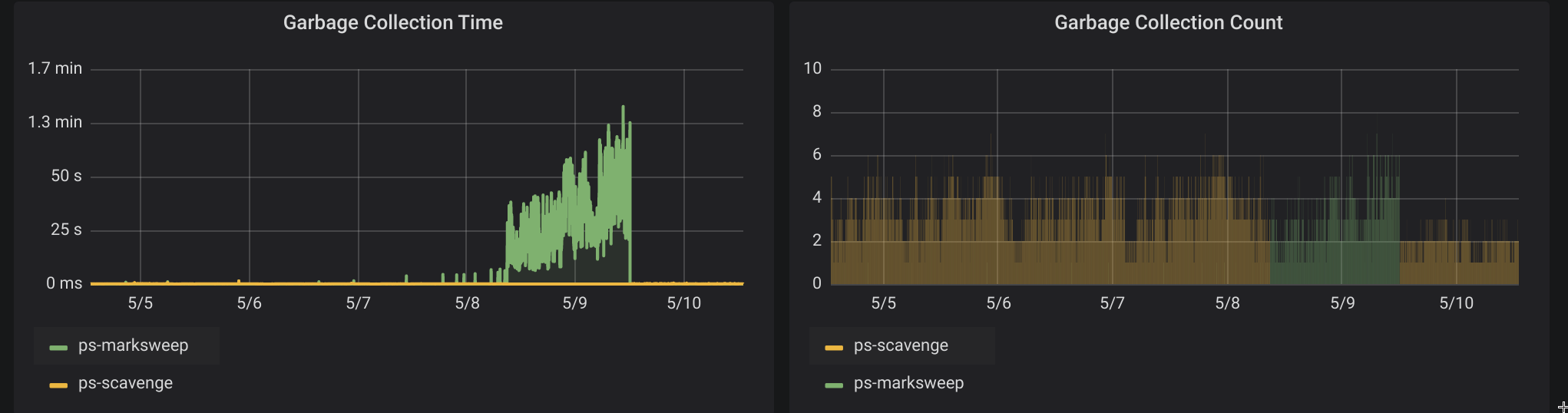
看情况很可能是内存泄漏了,接着看一下内存统计
jmap -histo
发现一个不该存在如此多的对象竟然有200w+个:
1 | num #instances #bytes class name |
这个时候,进程不响应Jmx的请求了,埋点的监控诊断无法正常进行,并且这个时候已经是业务低峰期,干脆直接dump下内存,保留线程栈,然后重启应用。重启后业务恢复正常。
分析泄漏点
根据代码,这个XXXAction是FrokJoinPool中的任务,200w+任务全部积压在这个队列里没有有效消费。直接通过前面保留的线程栈,可以看到这个ForkJoinPool的四个线程全部Waiting在这一行:
1 | - waiting on <0x00000006504b1610> (a io.netty.channel.DefaultChannelPromise) |
根据代码上下文,这里是我们的一个RpcClient在建立连接,正在等待Netty回调连接成功与否,但是这个回调一直没有产生,就直接hang死在这里了。
分析Dump下来的内存找到泄漏原因
打开MAT分析Dump下来的内存,直接找到处于Waiting state 状态的DefaultChannelPromise对象,这个对象实际上是持有Netty的NioSocketChannel对象的,通过持有链,可以找到正在尝试连接的RpcServer的ip。沟通运维最近的操作得知,这个ip地址所在的机器A之前有一个正常的RpcServer,之后由于服务器资源调整,迁移到了另外一台服务器B,也就是说,泄漏的这个进程一直在尝试连接一个关掉的服务器A,随后hang死在awaitUninterruptibly。
正常情况下,Netty client 链接一个不通的ip & port,肯定是会回调唤醒等待在DefaultChannelPromise的线程的。为什么会无法唤醒呢?
这个时候,旁边的同事看了业务代码,提示这个业务无法连通RpcServer的时候,会不断shutdown掉RpcClient,通过查看代码,发现这个shutdown操作,会把Netty的EventLoop给干掉。EventLoop都干掉了,自然没线程去跑DefaultChannelPromise的回调通知了。
捋清泄漏原因
- A服务器迁移,原有IP失效
- 有一个业务还有任务GG需要A服务器的依赖去执行,不断提交任务到ForkJoinPool
- ForkJoinPoll 中连接A服务器是同步等待的
- 业务自身的线程没有做好这个状态检测,发现任务GG还没完成,竟然直接Shutdown掉上一次的RpcClient,然后再次提交一次新的任务到ForkJoinPool。如果提交和shutdown这个时候,ForJoinPoll上一次的任务正在await中,永远也没法唤醒了。
hang死复现
hang死并且造成泄漏的表面原因是业务流程本身有逻辑上的问题,但本质上是因为Netty的shutdownGracefully没有处理好所有的Future导致的,这个bug可以通过下面的代码很简单就复现:
1 | public void testNetty() { |
代码在4.0.27.Final版本主线程会hang死,在最新的4.1.32.Final版本已经修复这个问题。
相关issue
给RPC框架提了个issue,RpcClient#shutdown 极端情况可能会出现hang死情况 #65,作者已经升级了Netty依赖版本。